
Deep dive into Kubernetes CronJob
Kubernetes CronJob are very useful, but can but hard to work with: parallelism, failure, timeout, etc. The official documentation and API reference are quite complete, I'll try below to give real-world examples on how to fine-tune your CronJobs and follow best practices.
Similar to a regular cron, a Kubernetes CronJob runs commands at a given time interval (cron schedule, following cron syntax), creating 1 (or more, see below) Kubernetes Job (hence Pods) per execution.
Example definition of a CronJob:
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: my-cron
namespace: default
spec:
# Run every 5 minutes
schedule: */5 * * * *
concurrencyPolicy: Forbid
backoffLimit: 2
startingDeadlineSeconds: 600
successfulJobsHistoryLimit: 0
failedJobsHistoryLimit: 1
suspend: false
jobTemplate:
spec:
activeDeadlineSeconds: 300
template:
metadata:
labels:
app: my-cron
spec:
activeDeadlineSeconds: 420
containers:
- name: cron
image: my-repo/cron:latest
Let's explain the main properties:
spec.concurrencyPolicy:Forbid: if previous Job is still running, skip execution of a new JobReplace: stop running instance of the job and start a new oneAllow: multiple instances of the job can run in parallel
spec.schedule: cron schedule in cron formatspec.startingDeadlineSeconds: optional deadline to start the job if failed to start on schedule (ie. job already running with conncurrency policy set toForbid)spec.suspend: set astrueto disable cron (does not affect already running jobs)
As you can see, spec.jobTemplate.spec is actually the spec of a Job, itself containing the spec of a Pod in it's template.spec property. That means that we can use all capabilities of Jobs and Pods when using CronJobs.
Among others, the following ones may especially be useful:
spec.jobTemplate.spec.activeDeadlineSeconds:- Maximum duration of the Job before Kubernetes tries to stop it
- This deadline is relative to Job creation, Pod may take some time to start, for instance when pulling image is necessary
- Set this value only if you know what you are doing
spec.jobTemplate.spec.backoffLimit:- Maximum number of retries before marking this Job as failed when Pod fails (exit code > 0) or Pod deadline exceeded
- Defaults to 6, set to 0 for no retry possible
spec.jobTemplate.spec.template.spec.activeDeadlineSeconds:- Maximum duration of the Pod before Kubernetes tries to stop it
- If Job
backoffLimitis > 0, a new Pod will be created until reached
CronJobs explained visually
Usage of activeDeadlineSeconds on Pod definition:
.png)
CronJob shown below is scheduled to run every 5 minutes, with a Job active deadline set to 540 seconds, and an execution time of the job greater than 600 seconds:
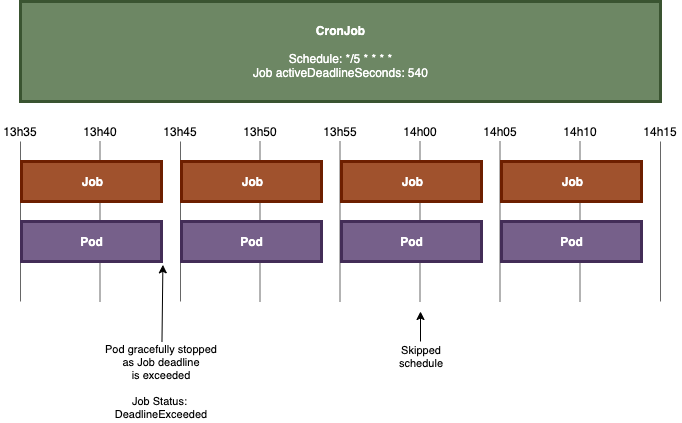
CronJob shown below is scheduled to run every 5 minutes, with a Job active deadline set to 900 seconds, and an execution time of about 600 seconds:
.png)
CronJob shown below is scheduled to run every 5 minutes, with a Pod active deadline set to 420 seconds, and an execution time greater than 420 seconds:
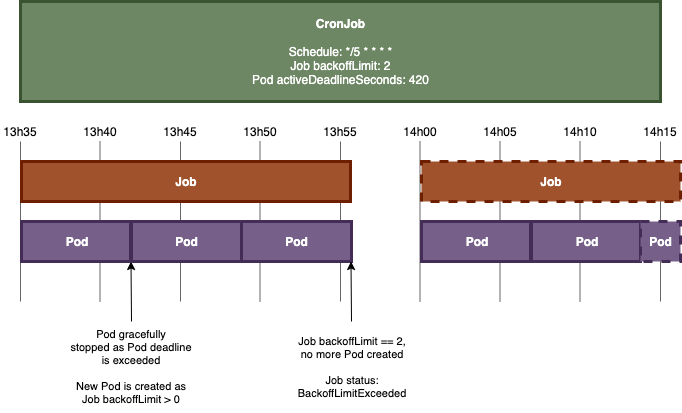
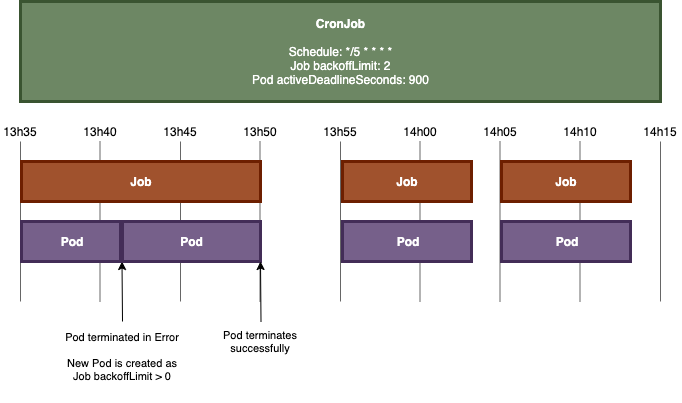
CronJob shown below is scheduled to run every 5 minutes, with a Pod active deadline set to 900 seconds, an execution time of about 600 seconds, and a failing execution:
Best practices
Avoid running all jobs at the same time
Most of the time, Cron jobs are scheduled to run every minute, every 5 minutes, or hour, which translate respectively to * * * * *, */5 * * * * and 0 * * * * in cron syntax.
As the number of CronJobs begins to grow on your cluster, you'll notice resources usage peaks every hour (all cron expressions above match), every 5 mins (2 expressions match), etc.
This may cause unnecessary cluster autoscaling, high network throughput affecting other workloads, race conditions, etc.
Prefer alternative execution schedules, for instance:
- Every 5 minutes:
4,9,14,19,24,29,34,39,44,49,54,49 * * * * - Every 6 minutes:
*/6 * * * *
Use resources efficiently
As CronJobs run through Pods, it is strongly recommended to define resources requests and limits.
Although most cron workloads will run on a single thread (ie. PHP script), thus using at most 1 core, you may want to define a lower CPU limit, so you do not need to request too much resources.
This is especially true when a limit of (for instance) 0.25 CPU instead of 1 would not have a big impact on execution time, or if execution time is not a big issue. That would allow only requesting 0.25 CPU, therefore avoiding potential need of cluster autoscaling when multiple cron jobs run at the same time.
You should whenever possible request and limit resources to as low as possible.
Handle termination signal
As any other Kubernetes workload, Pods created by CronJobs may be interrupted at any time, receiving a TERM signal on PID 1 of the container (if no preStop hook is defined).
This signal should be handled properly by the running task, so it is not "hard-killed" after the termination grace period (30s by default).
Atomic non-blocking cron
Many applications and frameworks have an embedded cron scheduler, which will be ran using a single cron script.
This not optimal as a long running cron task may block others. You should better split tasks in groups or even run tasks individually in separate Kubernetes CronJobs.
Pitfalls
Timezone
When scheduling CronJobs at specific hours (ie. 0 5 * * * to run everyday at 5:00), carefully check your Nodes timezone (which will be used by Kubernetes CronJob Controller to schedule Jobs).
Also be careful of timezone changes (DST) twice a year, as jobs may be skipped or ran twice.

I'm Michael BOUVY, CTO and co-founder of Click&Mortar, a digital agency based in Paris, France, specialized in e-commerce.
Over the last years, I've worked as an Engineering Manager and CTO for brands like Zadig&Voltaire and Maisons du Monde.
With more than 10 years experience in e-commerce platforms, I'm always looking for new challenges, feel free to get in touch!