
Understanding MySQL's InnoDB buffer pool

For many years now, I've heard a lot about famously known InnoDB's buffer pool: what size should be set for innodb_buffer_pool_size parameter, what it contains, how it could be warmed up.
I've also been told several times that "once your tables are in memory, all queries are super fast as there is no more disk I/O". All these statements lead me to write this blog post to (try to) explain how InnoDB's buffer pool works and what it contains.
Buffer pool content
InnoDB data is stored in 16 KB pages (blocks), either on disk (ibdata files) or in memory (buffer pool). Each one of these pages may contain one or more row.
The buffer pool is basically a cache for these pages: once a page's content is requested by a query, the page is cached in the buffer pool.
You may be wondering what kind of data is stored in these pages. Short answer: indexes (on a size point of view). MySQL offers a very useful INFORMATION_SCHEMA database, which contains since version 5.5 a table named innodb_buffer_page.
This table holds 1 record (row) per page in the buffer pool, including interesting data such as what the page contains. Take a look at MySQL's official documentation of this table if you want details on it's columns and data. Now let's have a little fun with this table.
Number of pages in buffer pool
Query:
select count(*) from information_schema.innodb_buffer_page;
Output:
+----------+
| count(*) |
+----------+
| 262142 |
+----------+
We've got 262 142 pages in our buffer pool × 16 KB per page = 4 194 272 KB. This value matches innodb_buffer_pool_size parameter.
Page types in buffer pool
Query:
select
page_type as Page_Type,
sum(data_size)/1024/1024 as Size_in_MB
from information_schema.innodb_buffer_page
group by page_type
order by Size_in_MB desc;
Result:
+-------------------+--------------+
| Page_Type | Size_in_MB |
+-------------------+--------------+
| INDEX | 158.66378689 |
| UNKNOWN | 0.00000000 |
| TRX_SYSTEM | 0.00000000 |
| SYSTEM | 0.00000000 |
| FILE_SPACE_HEADER | 0.00000000 |
| IBUF_BITMAP | 0.00000000 |
| EXTENT_DESCRIPTOR | 0.00000000 |
| ALLOCATED | 0.00000000 |
| INODE | 0.00000000 |
| BLOB | 0.00000000 |
| UNDO_LOG | 0.00000000 |
| IBUF_FREE_LIST | 0.00000000 |
| IBUF_INDEX | 0.00000000 |
+-------------------+--------------+
As you can see, merely INDEX pages are cached in the buffer pool. Some quick explanations about the most important page types:
- INDEX: B-Tree index
- IBUF_INDEX: Insert buffer index
- UNKNOWN: not allocated / unknown state
- TRX_SYSTEM: transaction system data
But where the heck is table rows data? In an index!
The clustered index, which is almost always based on table's primary key (internally generated if missing), and stores data in it's leaves.
As nodes/leaves are sorted upon their primary key value, it is recommended to use auto increment, or an always increasing value.
Note that (except for fullscans) this index needs to be traveled using the primary key(s) of the row(s) we want to retrieve. Also, primary key is always stored in (secondary) indexes, for InnoDB to lookup for requested row's data.
Buffer pool usage per index
Query:
select
table_name as Table_Name, index_name as Index_Name,
count(*) as Page_Count, sum(data_size)/1024/1024 as Size_in_MB
from information_schema.innodb_buffer_page
group by table_name, index_name
order by Size_in_MB desc;
Result:
+--------------------------------------------+-----------------+------------+-------------+
| Table_Name | Index_Name | Page_Count | Size_in_MB |
+--------------------------------------------+-----------------+------------+-------------+
| `magento`.`core_url_rewrite` | PRIMARY | 2829 | 40.64266014 |
| `magento`.`core_url_rewrite` | FK_CORE_URL_... | 680 | 6.67517281 |
| `magento`.`catalog_product_entity_varchar` | PRIMARY | 449 | 6.41064930 |
| `magento`.`catalog_product_index_price` | PRIMARY | 440 | 6.29357910 |
| `magento`.`catalog_product_entity` | PRIMARY | 435 | 6.23898315 |
+--------------------------------------------+-----------------+------------+-------------+
We can see here the clustered (PRIMARY) indexes holding rows data.
InnoDB buffer pool size
So how much memory should we allocate in the buffer pool size setting? I recommend the following rule of thumb:
rows data size + indexes size (excl. clustered) + 20%
Altough it might be a "secure" option to calculate this size based on the whole data set, you might prefer calculate it based on your working set size, which corresponds to frequently used data (do you really need those old log rows in memory?). This is especially useful when your whole dataset wont fit into memory.
InnoDB buffer pool usage examples
Buffer pool size vs. disk reads
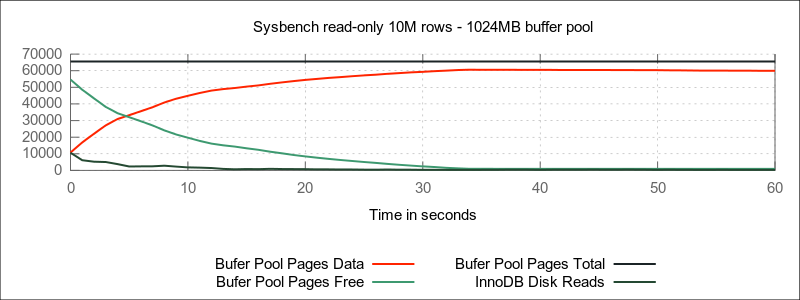
In the above graph, we can clearly see the impact on disk reads (status variables innodb_buffer_pool_reads) getting closer to 0 as the buffer pool size grows.
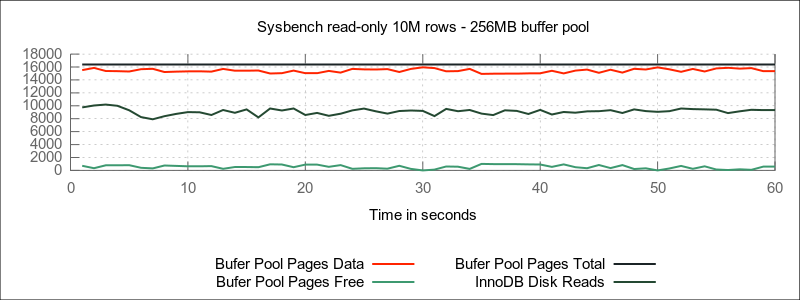
On the contrary, in the graph below, with a buffer pool smaller than the size of the working set, disk reads remain at the same level, as old pages are constantly flushed from the buffer pool for new ones.
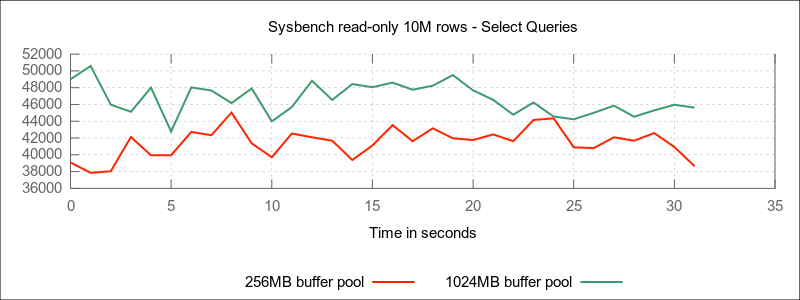
Quite obviously, buffer pool size also has a significant impact on performance (~ 1024MB data set):
InnoDB buffer pool warmup
It may take a while under a regular workload to store your entire working set data into the buffer pool, after restarting MySQL for instance.
"Manual" warmup
Running SELECT queries against your InnoDB tables will load necessary pages into memory (the buffer pool).
Therefore, SELECT COUNT(*) may be very useful, as it will load the whole clustered index into memory (actually as much as available).
Secondary indexes may be loaded into memory with simple queries, for instance by adding a "catch-all" (ie. <> 0) WHERE clause on the first column of an index. Using a given index could be forced if needed, see MySQL index hints.
Dump & restore
For those who use recent versions of MySQL (5.6+), Percona Server (5.5.10+) or MariaDB (10.0+), automatic buffer pool content dump at shutdown and restore on startup can be enabled. In MySQL 5.6+, define the following configuration variables:
innodb_buffer_pool_dump_at_shutdown=ONinnodb_buffer_pool_load_at_startup=ON

I'm Michael BOUVY, CTO and co-founder of Click&Mortar, a digital agency based in Paris, France, specialized in e-commerce.
Over the last years, I've worked as an Engineering Manager and CTO for brands like Zadig&Voltaire and Maisons du Monde.
With more than 10 years experience in e-commerce platforms, I'm always looking for new challenges, feel free to get in touch!